核心导视:图解生成式网络全貌
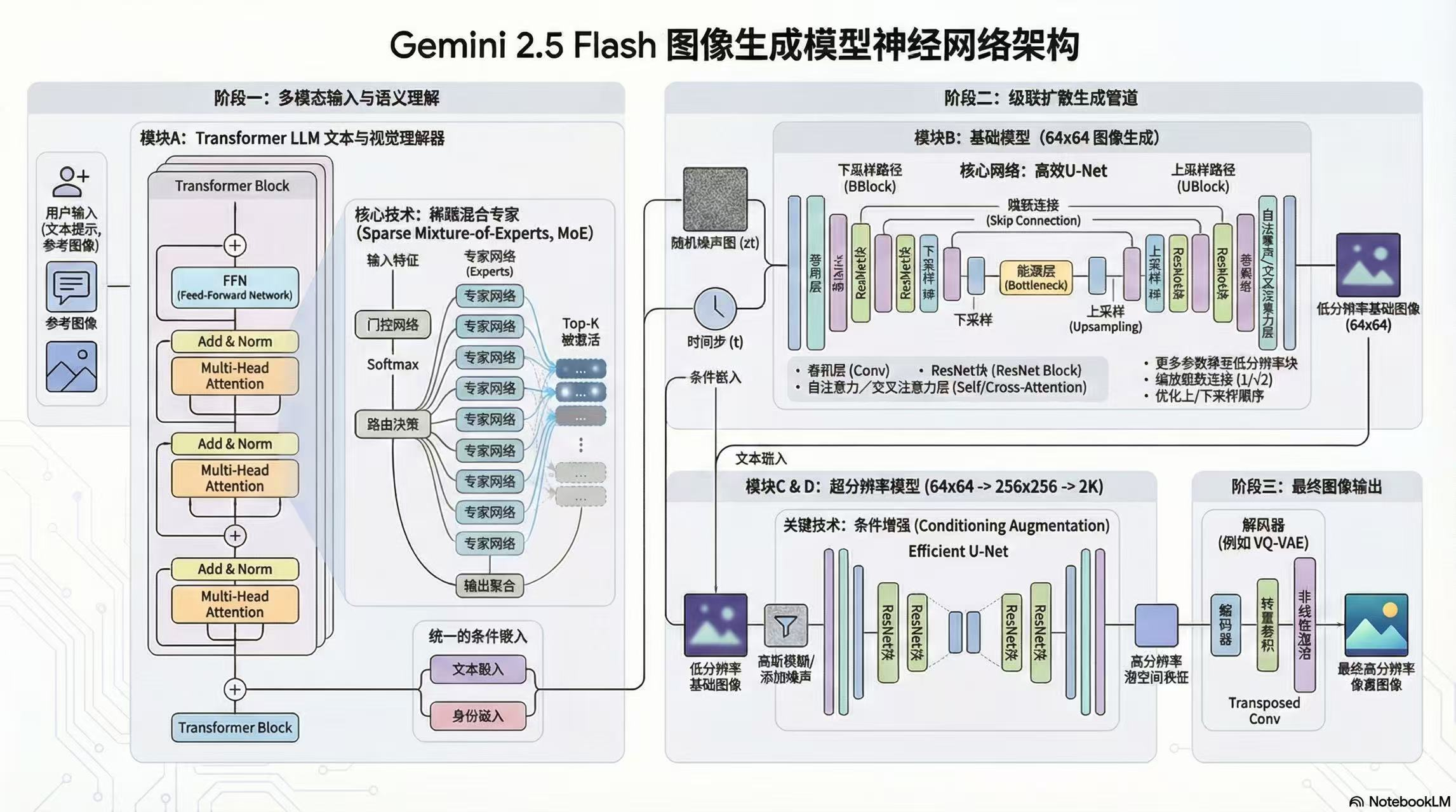
Nano Banana (类似 Gemini 2.5 Flash Image 架构) 的核心逻辑是 使用 T5 的复杂文本理解力,调度底层的混合专家算力池,在 VAE 的潜空间中,通过级联 U-Net 像剥洋葱一样刮除噪声,最终冲洗出高清图像。
一、逻辑基石:全连接层 (Dense Layer) 的前向与反向传播
全连接层是神经网络处理特征的最核心单元,任何庞大的网络,其“思考”的源头都始于:$z = W \\cdot x + b$。我们通过一个 $3 \\times 2$ 的矩阵来演示计算和权重更新的全过程。
1. 前向传播 (Forward Pass)
设定一个拥有两个特征的输入向量 $x$,以及具有 3 个神经元的权重矩阵 $W$ 和偏置向量 $b$:
线性变换结果:$z = W \cdot x + b$
为了让模型具备超越线性规律的拟合能力,我们将 $z$ 输入 ReLU 激活函数 $a = \max(0, z)$,小于等于0的数值被剔除,输出结果保持为:
2. 损失计算 (Loss) 与反向传播 (Backpropagation)
模型给出预测后,需要与我们的期望标准目标值 $y$ 进行比对:
误差向量 (Error) $= a - y = \begin{bmatrix} 1 \\ 5 \\ 0 \end{bmatrix} - \begin{bmatrix} 1 \\ 3 \\ 0 \end{bmatrix} = \begin{bmatrix} 0 \\ 2 \\ 0 \end{bmatrix}$
总损失平方和 $= 0^2 + 2^2 + 0^2 = 4$
责任分摊与权重更新: 误差主要出在中间的第二个神经元(误差为2)。通过链式法则计算,该神经元针对输入特征 $x_1(2)$ 和 $x_2(1)$ 产生的局部梯度:
• 权重 $W_{2,2}$ 的梯度 = $\text{误差信号}(4) \times x_2(1) = 4$
网络便依据这组梯度逆向调整该权重,使得下一次遇到相似输入时,总损失 $Loss$ 变小。
二、效率引擎:混合专家架构 (MoE) 深度剖析
现代大模型(如 Nano Banana)为了在拥有海量参数的同时维持极低的高速推理延迟,将传统庞大迟缓的密集型全连接层替换为了 Sparse Mixture-of-Experts (稀疏混合专家网络)。
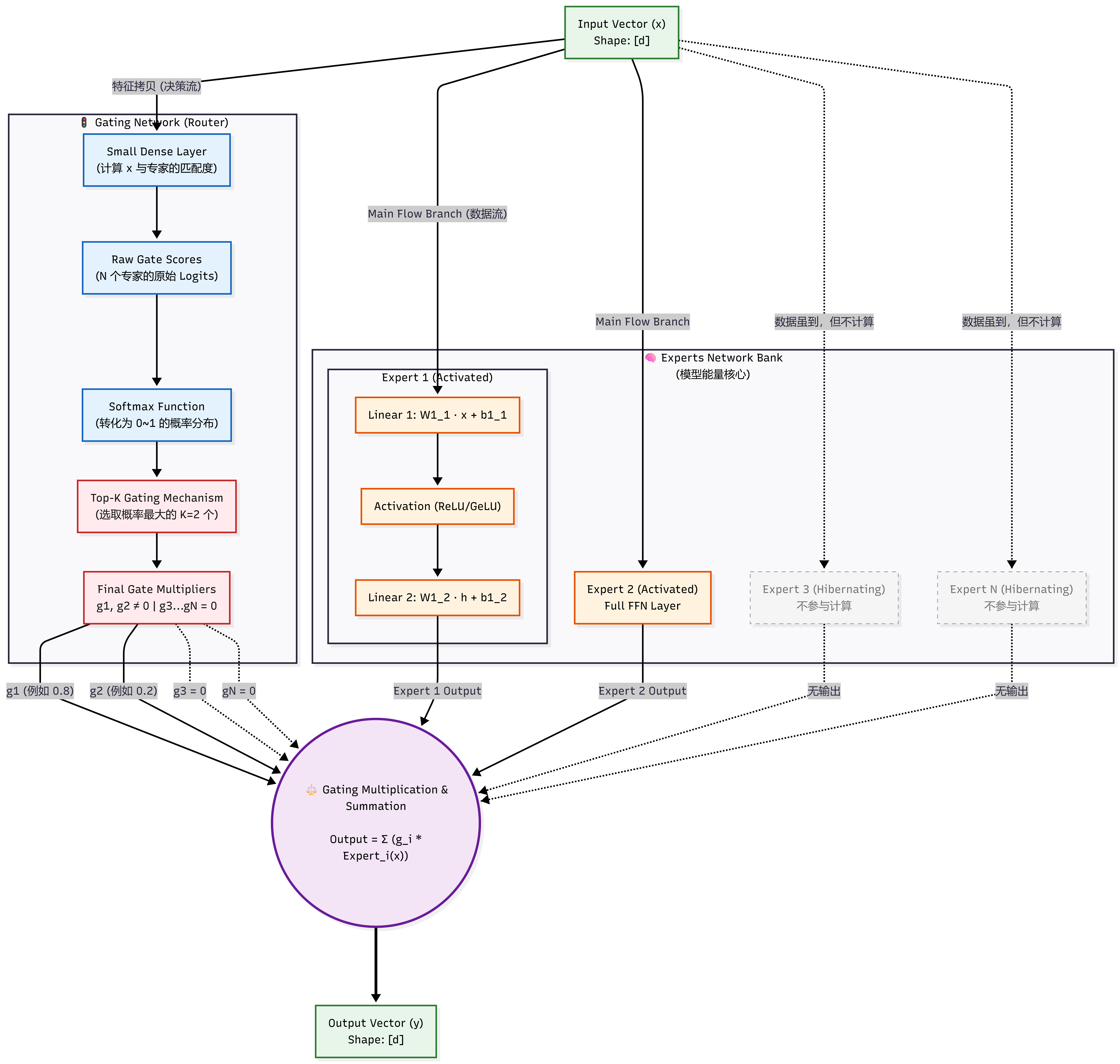
1. 门控路由器预测 (Router Gating)
路由器 (Router) 是决定算力去向的核心指挥官,其本质是一个小型的全连接矩阵 $W_{gate}$。针对同样的输入 $x = [2, 1]^T$,它计算出该特征与底层库中(假设3个)多位专家的匹配程度:
$L = W_{gate} \cdot x = \begin{bmatrix} 2 \\ 1 \\ -1 \end{bmatrix}$
经过 Softmax 函数 转换为加和为 1 的概率:专家1(0.71),专家2(0.26),专家3(0.03)。
2. Top-K 极其稀疏激活 (Sparse Activation)
这是省电提速的核心:设定 $K=2$ (Top-2 门控),模型只会唤醒匹配度最高的专家 1 和专家 2,而专家 3 及其内部成千上万的参数矩阵将处于休眠状态,零计算开销!
3. 加权输出与误差追踪
唤醒的专家独立处理数据并交卷。最终输出是两者按门控概率混合的产物:
最终输出 $Y = 0.71 \cdot \begin{bmatrix} 10 \\ 0 \end{bmatrix} + 0.26 \cdot \begin{bmatrix} 0 \\ 10 \end{bmatrix} = \begin{bmatrix} 7.1 \\ 2.6 \end{bmatrix}$
训练核心(责任分发): 若系统给出的正确目标为 $T = [7.1, 0.6]^T$,系统总误差为 $Y - T = [0, 2]^T$。在反向传播时,每位专家领取的“罚单(误差回传量)”严格受其获得的门控权重影响。例如专家2仅分摊 $0.26 \times [0, 2] = [0, 0.52]$,休眠的专家3分摊严格为 0,这保证了大规模并发训练和隔离优化的效率。
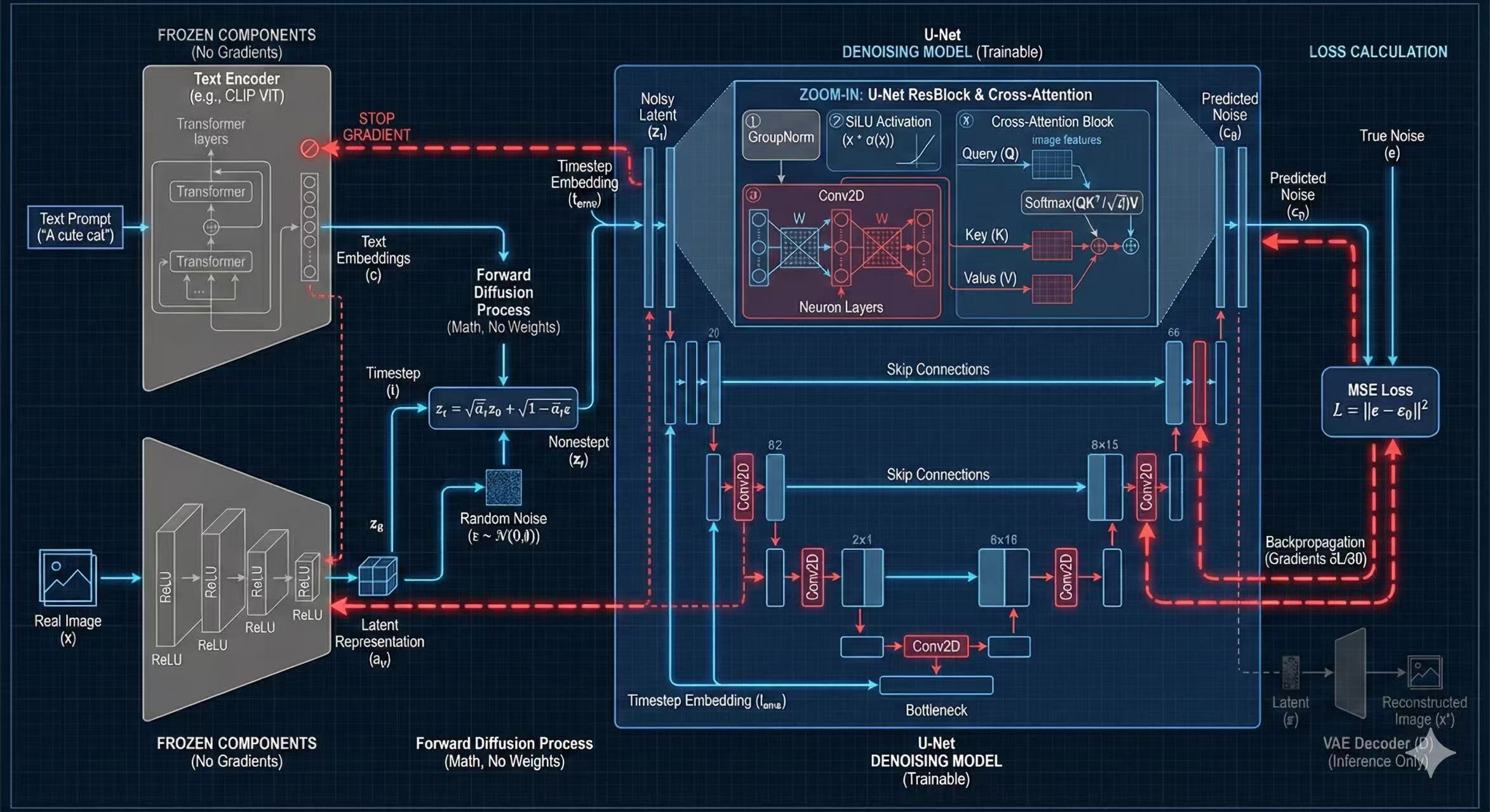
三、视觉捕获器:U-Net 与局部卷积 (Convolution)
全连接层将所有信息揉碎融合,而卷积层(U-Net 的血脉)如同一把拿着微型扫描器的游标卡尺,专门通过“滑动窗口”模式定位边缘和纹理特征。
矩阵乘法在滑动:寻找横向边缘
设我们输入一个 $3 \times 3$ 的图像局部 $I$,上半部亮,下半部暗。同时模型有一个随机权重的 $3 \times 3$ 滤波器 $F$:
操作:“按位置对应相乘后求和”。由于结构匹配,最终输出得分为 30。这种极其强烈的正向响应等同于向神经网络大声宣告:“我在此矩形区域提取到了显著的横向画面边缘!”
在 U-Net 的左右两侧,这套操作通过“下采样(左半部不断提取深层特征信息)”和“上采样(右半部结合信息还原高清结构)”像字母 U 一样流转,最终完成去噪生成。
四、高清密码:双通道融合与级联 U-Net
Nano Banana 和 Imagen 这类模型采用的是级联扩散 (Cascaded Diffusion)。它不是一次算完,而是分步骤接力的。其中,负责从草图向超高清推进的“超分辨率 U-Net”,其训练和预测的核心在于 “双通道矩阵拼接 (Concatenation)” 操作。
矩阵沙盘演示:如何一边看图一边去噪?
在一维的极管空间内,U-Net(如上图第二级)接收到了双通道输入。一部分是等待它去噪的高分辨率模糊数据 ($HR_{noisy}$),另一部分是基础模型传递过来的低分辨率草图参考 ($LR_{up}$,其已被机械放大并对齐尺寸)。
通道 2: $LR_{up} = \begin{bmatrix} 8 & 8 & 2 & 2 \end{bmatrix}$
拼接形成 $2 \times 4$ 双通道矩阵:$X = \begin{bmatrix} 9 & 7 & 4 & 1 \\ 8 & 8 & 2 & 2 \end{bmatrix}$
网络会利用一个深度尺寸为 2 的多通道卷积滤波器(如 $W = [[1, -1], [0, 1]]$)在此双通道上滑动,同时提取“局部噪声细节”与“全局构图轮廓”。针对前两列区块,计算混合特征结果为:
这为超分放大模型在去噪过程中提供了不会偏离骨架重心的锚点。在模型训练时,更讨巧的一步是:直接利用已知完美的高分辨率原图人工压缩成低分辨率图喂给 $LR_{up}$。这彻底解除了前后两套神经网络并行训练的依赖阻塞!
五、跨越时空:正弦位置编码与去噪逻辑
自造“标准答案”
在有监督学习中(如图像识别),标准答案是常人打标的目标。而在扩散模型训练时,人类通过计算机在时间步 $t$ 内随机生成的确定噪声,即该轮训练的最终目标矩阵 $T$。U-Net 瞎猜一通给出噪声 $y$,两者相减即得误差矩阵 $y-T$,这便是整个大网络参数回推优化的起点。
正弦位置编码 (Sinusoidal Positional Encoding) 解决数值灾难
在几十次加去噪的循环中,U-Net 需要知道自己“到底在哪一步”。如果在细微的标准化网络参数中,强行输入纯整数 `37` (第37步),将会导致乘法结果雪崩和梯度爆炸。
于是参考 NLP 技术,工程师用一组正弦和余弦函数组 (Sine/Cosine curves),将 `37` 这个数字翻译为了一组数值范围永远局限在 `-1` 和 `1` 之间的多维浮点数向量(如 $[0.84, -0.52, 0.11]$)。这种三角函数的平滑连续特性,赋给模型能够自然衡量“第37步与第38步之间关联与缓冲余量”的时间刻度感!
六、翻译官的大脑:Transformer 与 T5 文本语义空间
相较于传统采用图文弱关联算法的 CLIP 模型,Nano Banana 选择了让专门的庞大语言学霸 T5 Encoder 去理解诸如“一只绿色的香蕉”等包含复杂逻辑词、修饰语的复杂提示词。
1. 图像的积木拆解 (Patching 与 Flattening)
Transformer 只认一维流动的文本队列。因此引擎先对 2D 高清图痛下杀手。将一张 $48 \times 48 \times 3$ 的彩图,切分为一个个 $16 \times 16$ 的小方块,共计 9 块 ($3 \times 3$)。这 9 个 3D 物块被无情展平 (Flatten) 为 $1 \times 768$ 的长条状列向量。最后,借助一个投影升维矩阵 $W_E ~(768 \times 4096)$ 的魔法转化:
完美将一团毫无生机的底层色彩数值,拉入了等同于 T5 文本 Token 的高维语义思考空间。
2. 交叉注意力机制 (Cross-Attention):让像素强听母语
面对冻结在原地不妥协的 T5 模型吐出的极复杂文本向量,U-Net 必须在内部矩阵自行“同传翻译”。计算点积是相认的核心:
图块 $K(\text{狗脸}) = [0.7, 0.8]$,图块 $K(\text{背景车}) = [-0.8, -0.2]$
小狗与狗脸的匹配度 $= (0.8\times0.7) + (0.9\times0.8) = 1.28 \to \text{相关度极高}$
小狗与背景的匹配度 $= (0.8\times-0.8) + (0.9\times-0.2) = -0.82 \to \text{错乱}$
随后模型利用巨大的 Softmax 百分比,令对应的图块权重占据极高主导,这批视觉特征所携带的具体 Value矩阵即可直接被吸收入模型。通过成千上万次强拧在一起的注意力回算,U-Net 重构了自己的跨界认知规律。
七、工业算力救赎指南:VAE 潜变量与 LoRA 秩矩阵微调
1. VAE: 在抽象真空中微雕
一张 $1024 \times 1024 \times 3$ 的庞大彩图,将吞噬一切运行内存。工程师引入 **变分自编码器 (VAE)** 充作 WinRAR 解压缩机制。U-Net 在 Nano Banana 中的大部分去噪战斗,实际上从未见识过光影斑斓的真实世界。 它仅在一个缩放为 $128 \times 128 \times 4$(原空间 $1/64$ 占比体积)的高维潜变量空间 (Latent Space) 闭环循环。在这个仅保留“边界、轮廓、语义”抽象的世界去噪完毕后,最终输出才会交由 VAE 的 Decoder(解码器)注入光照和细节,“冲洗”成 RGB 彩画。
2. LoRA 补丁魔法:极度压缩训练消耗
不重训整个百亿百科全书,只在新书页夹一张便利贴,这便是 LoRA 的“低秩”拆解哲学。
它完全冻结原生重达万吨的主干权重 $W_0$,对于一个需要更新的 $\Delta W$ 外挂体积分支进行拆分:
如果目标参数量大到 $10000 \times 10000 = 1$亿,通过设置秩 $r=4$,系统只需要去训练 $10000 \times 4$ 和 $4 \times 10000$ 这两个微小的小矩阵。它们加在一起只有 8万个参数。整体算力足足被降维缩减了惊人的 1250倍!